Performance et protocole de communication (USB)
2 décembre 2025
HID
Nous avons travaillé sur la lecture d’une manette USB, qui serait vraiment pratique pour piloter un robot. Nous sommes tombés sur un os, tout bête, mais qui nous a fait perdre du temps. TinyUSB prévoit par défaut 256 octets pour le descripteur HID. Et il nous a fallu un peu de temps pour trouver cette limite et réaliser que notre descripteur faisait 499 octets...
Bref, nous reportons notre code sur l’HID à plus tard.
Performances brutes
Nous reprenons alors nos essais de performances avec un Raspberry Pi Pico en client. La différence de résultats, entre un PC hôte et un Raspberri Pi Pico hôte, est notable :
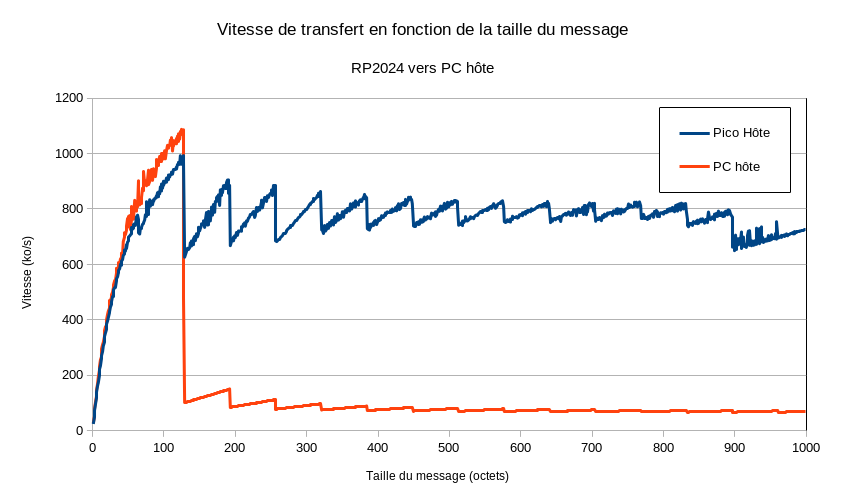
Performance USB CDC - 1 seul périphérique
Dans le cas du Raspberri Pi Pico hôte deux choses nous surprennent :
- Le pic de vitesse pour des paquets de 120 octets dépasse celui de l’ordinateur.
- La vitesse s’effondre lorsque la taille du paquet augmente pour se stabiliser à 70 ko/s
Quand nous regardons le temps passé pour émettre le message, nous nous apercevons d’un temps qui augmente par palier de 1 milliseconde à chaque bloc de 64 octets.
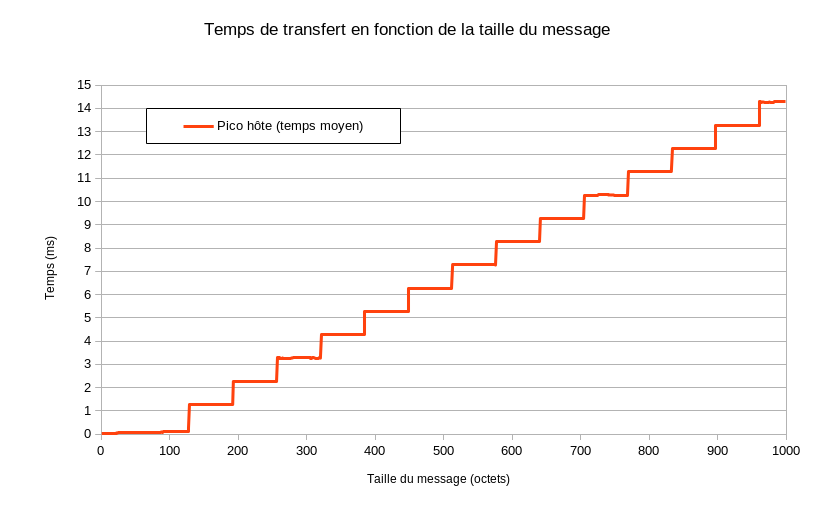
Temps pour envoyer un message
Nous supposons qu’il y a quelque chose dans TinyUSB qui est responsable de ce temps d’attente, mais sans certitude.
Le découpage des messages
La réception des messages est un point assez sensible. Avec l’I2C, nous n’avions pas de soucis. Une trame I2C, délimitée par le bit de stop et le bit de fin, contenait un seul message : une réception, un message, un traitement. Facile ! ou presque...
Avec l’USB, ou d’autres protocoles modernes comme l’UDP, la trame reçue peut contenir plusieurs messages. Elle peut ne pas contenir le début du 1er message, ni la fin du dernier message.
Notre première étape est de stocker les données reçues (avec tuh_cdc_read()) dans un tampon tournant avec :
- un pointeur vers où écrire les prochaines données ;
- un pointeur vers où lire les données.
Enfin, nous avons un protocole qui défini différents messages, répartis en 2 familles :
- Les messages ASCII, commencent par ’>’ et se terminent par ’\n’
- Des messages binaires, commencent par ’r’, ’w’ ou ’d’. leur entête donne leur taille et ils se terminent tous par ’\0’
Nous recopions le tampon tournant vers un tampon normal pour l’analyser. Ce tampon est parcouru afin de détecter un caractère de début. Une fois le caractère de début détecté, la suite est parcourue jusqu’à trouver le caractère fin et sa position. Dans le cas des messages binaires, cette position est comparée avec celle déduite de la taille du message. Évidemment, à chaque étape, il faut prévoir le cas où nous arrivons à la fin du tampon.
Lorsqu’un message complet est détecté, celui-ci est ajouté à une pile de message qui sera traitée. Le pointeur de lecture du tampon tournant est mise à jour.
Honnêtement, nous nous sommes un peu emmêlé les pinceaux sur cette partie. Ce serait à refaire, nous ferions autrement. L’avantage de notre méthode est la simplicité d’envoi et de détection d’un message de texte. L’inconvénient est qu’avoir plusieurs types de message multiplie les codes de détection des messages, complexifiant l’architecture globale.
Cet art de découper les message s’appelle le framing. L’une des difficultés est le caractère de fin du message qui pourrait être contenu dans le corps du message (sauf à envoyer des données en ASCII). Deux options que nous avons étudiées mais pas retenues :
- L’une des solutions (byte stuffing / bourrage d’octets) consiste à doubler chaque valeur qui serait une valeur de fin de message, sauf dans le cas où il s’agit réellement de la fin du message
- L’autre, Consistent Overhead Byte Stuffing (COBS), consiste à se brider à des messages de 254 octets et à choisir une valeur arbitraire pour la fin du message (généralement 0). Le protocole ajoute un octet qui indique la position du prochain octet égale à la valeur de fin de message. Si c’est une valeur du message, cette valeur est remplacée par la position du prochain caractère qui vaut la valeur de fin de message. Les exemples de Wikipédia sont très parlant.
Merci à @madahin[Sharp’Attack] et à Wix [Girafes] (Legend) pour ces découvertes !
Une évolution possible / probable serait d’utiliser un entête commun à tous nos messages et de terminer le message par une somme de contrôle et un caractère de fin de message.
Bref, ce n’est pas la partie dont nous sommes le plus fier et mettre ceci au point nous a causé bien des soucis. À tel point que nous avons eu recours à un débogueur pour Raspberry Pi Pico, ce qui fut l’occasion pour nous d’écrire notre article de prise en main du débogueur.
Partie applicative
Nous fonctionnons uniquement avec des états. Chaque carte envoie à l’hôte USB ses données. L’hôte USB dispose d’une mémoire par carte périphérique et stocke les données reçues en écrasant les précédentes.
Les périphériques peuvent envoyer une demande de lecture, en indiquant l’adresse de la carte, l’adresse du registre à lire et la taille des données demandées. L’hôte répond en envoyant les données stockées.
Après ces efforts nous avons testé le protocole pendant 3h30 avec d’un côté une carte qui lit un capteur de distance, de l’autre une carte qui allume ou éteint une DEL en fonction de la distance du capteur et au milieu notre hôte (ce à quoi nous pourrions rajouter le Pico qui nous servait de sonde de débogage, pour décrire le bazar...). Bref le test fut enfin concluant !
Commentaires
Il n'y a pas de commentairesAjouter un commentaire
Administration du site